O que é o cabeçalho http?
Com a ajuda de cabeçalhos http, uma trocainformações de serviço entre o cliente e o servidor. Esta informação permanece invisível para os usuários, mas sem ela, o funcionamento correto do navegador é impossível. Para usuários comuns, as informações sobre isso e as tarefas dos cabeçalhos http parecerão bastante complicadas, mas na verdade não contêm formulações difíceis. Isto é o que um usuário da web está enfrentando todos os dias.

O que são cabeçalhos http?
"HyperText Transfer Protocol" - exatamente assimo cabeçalho http é traduzido. Devido à sua existência, a comunicação cliente-servidor é possível. Se explicada em termos simples, pelo navegador envia uma solicitação, iniciando conexão com o servidor. Última, por padrão, aguarda um pedido de um cliente, processa e envia de volta um resumo ou resposta. Na caixa de pesquisa, o usuário "martelando" o endereço do site que começa com http: // e os resultados obtidos na forma da página aberta.
Quando o endereço do site é impresso no correspondentelinha, o navegador encontra o servidor necessário usando o DNS. O servidor reconhece o cabeçalho http (um ou mais) que o cliente envia para ele e, em seguida, emite o cabeçalho necessário. O conjunto obrigatório consiste em cabeçalhos já existentes e não encontrados.
Em geral, os cabeçalhos http são bastante eficazes. Eles não são visíveis na codificação HTML, eles são enviados antes das informações solicitadas. Muitos cabeçalhos são enviados automaticamente pelo servidor. Para enviá-lo em PHP, você deve usar a função de cabeçalho.

Interação entre navegador e site
O esquema de interação entre o navegador e o site é suficientesimples. Portanto, o cabeçalho http inicia a sequência de consulta, que é então enviada ao servidor. Em resposta, as informações necessárias pelo cliente são fornecidas. A propósito, o protocolo http já tem dezessete anos - o mais usado na Internet. É simples, confiável, funciona de forma rápida e flexível. A principal tarefa do http é solicitar informações do servidor da web. O cliente é o navegador e o servidor é ligthttp, apache, nginx. Se a conexão entre eles for bem-sucedida, o servidor receberá as informações solicitadas em resposta à solicitação. A informação http contém texto, arquivos de som, vídeo.
O protocolo pode ser um transporte para outros. A solicitação do cliente consiste em três partes:
- a linha de partida (tipo de mensagem);
- cabeçalhos (parâmetros de mensagem);
- corpo de informação (uma mensagem que é separada por uma linha vazia).
A linha de início é o elemento necessário da solicitação de cabeçalho http. A estrutura da solicitação do usuário consiste em três partes principais:
- Método Indica o tipo de solicitação.
- O caminho Essa é a sequência de URL que segue o domínio.
- O protocolo usado. Consiste na versão do protocolo e http.
Os navegadores modernos usam a versão 1.1. Em seguida, os títulos no formato "Nome: Valor".

Cache HTTP
A conclusão é que o armazenamento em cache fornece armazenamentoPáginas HTML, outros arquivos no cache (um lugar na memória operacional, no disco rígido do computador). Isso é necessário para acelerar o acesso a eles e economizar tráfego.
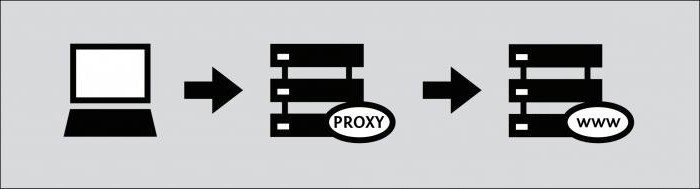
O cache tem um navegador do cliente, um gateway intermediário eservidor proxy. Antes de enviar uma mensagem para o URL, o navegador verificará a presença do objeto no cache. Se o objeto não existir, a solicitação é passada para o próximo servidor, onde o cache dos cabeçalhos http no servidor nginx é verificado. Gateways e proxies são usados por usuários diferentes, portanto, o cache é compartilhado.
O caching HTTP pode não apenas significativamenteacelerar o site, mas também fornecer uma versão mais antiga da página. Ao armazenar em cache o site, os cabeçalhos são enviados para a resposta. As informações solicitadas pelo protocolo HTTPS não podem ser armazenadas em cache.

Descrição dos cabeçalhos http
Alguns dos mecanismos de cache mais importantes sãoCabeçalhos http expira. Esses cabeçalhos relatam a data de expiração das informações fornecidas na resposta. Eles especificam a hora e a data em que o cache será considerado obsoleto. Por exemplo, este cabeçalho é assim: Expires: Wen, 30 Nov 2016 13:45:00 GMT. Essa estrutura é usada em quase todos os lugares, incluindo o armazenamento em cache de páginas e imagens. Se o usuário selecionar a data antiga, as informações não serão armazenadas em cache.
Os cabeçalhos de proxy HTTP estão na categoria de cabeçalholink. Eles não são armazenados em cache por padrão. Para que o cache funcione corretamente, cada URL deve corresponder a uma opção de conteúdo. Se a página estiver em dois idiomas, cada versão deverá ter seu próprio URL. O cabeçalho variável reporta o cabeçalho do cabeçalho da solicitação. Por exemplo, se a exibição da consulta depender do navegador, o servidor também deverá enviar um cabeçalho. Assim, o cache armazena várias opções de consulta e tipos de documentos. O cabeçalho de aceitação do TTP é necessário para compilar listas de formatos válidos para o recurso em uso, é bastante fácil trabalhar com ele, pois filtra os desnecessários.
Existem quatro grupos de títulos,que transmitem as informações de serviço. Estes são os cabeçalhos principais - eles estão contidos em qualquer mensagem do servidor e do cliente, solicitação e resposta, bem como a entidade. Este último descreve o conteúdo de qualquer mensagem do cliente e do servidor.
O cabeçalho de autorização HTTP é consideradoadicional. Quando a página da Web solicita autorização ao cliente, o navegador exibe uma janela especial com campos para inserir o login e a senha. Depois que o usuário insere seus dados, o navegador envia uma solicitação http. Contém o título "autorização".

Como posso ver os cabeçalhos?
Para ver o cabeçalho http, você precisa instalar plugins para o navegador, por exemplo, firefox:
- Firebug. Você pode ver os cabeçalhos na guia de rede, onde você seleciona todos. Este plugin tem funções que serão úteis para o desenvolvedor da web.
- Live cabeçalhos http. Um plugin simples projetado para visualizar cabeçalhos http. Usando-o, você pode gerar manualmente uma consulta.
- Membros Ghrome facilmente ver as manchetes quando eles clique no botão configurações, escolha Ferramentas de Desenvolvimento (obras líquidos).
Quando os plug-ins estiverem instalados, execute-os e atualize a página do navegador.
Métodos de consulta
Os métodos usados no HTTP têm semelhanças com as instruções que são passadas como uma mensagem para o servidor. Esta é uma palavra especial em inglês.
- Método GET. É usado para solicitar informações de um recurso. É com ele que todas as ações começam.
- POST. Com isso, os dados são enviados. Por exemplo, uma mensagem na rede social ou um comentário que o navegador coloca no corpo da solicitação POST e a envia para o servidor.
- CABEÇA O método tem semelhanças com o primeiro, mas executa uma função fácil. Apenas solicita metadados, excluindo a mensagem da resposta. Use este método se você deseja obter informações sobre arquivos sem fazer o download. Ele é usado se você quiser testar a eficiência dos links no servidor.
- PÔR. Carrega dados no URL. Envia grandes quantidades de dados.
- OPÇÕES Funciona com configurações de servidor.
- URI Identifica o recurso e contém o URL.

A estrutura da resposta http
O servidor responde às solicitações do cliente commensagens. A resposta consiste em várias linhas, nas quais a versão do protocolo é indicada, o código de status do servidor (200). Diz que mudou no servidor durante o processamento do pedido recebido:
- O status de "duzentos" indica o processamento bem-sucedido da informação. Depois disso, o servidor envia o documento para o cliente. As linhas restantes da solicitação indicam outras informações sobre as informações que estão sendo transferidas.
- Se o arquivo não for encontrado ou não existir, o servidor enviará o código do cliente 404, também é chamado de erro.
- O código 206 indica um download parcial do arquivo, que pode ser retomado depois de um tempo.
- O código 401 indica uma negação de autorização. Isso significa que a página solicitada é protegida por senha, que deve ser digitada para confirmar o login.
- Sobre o acesso proibido, diz o código 403. Proibições de visualização, download de arquivos ou vídeo é uma resposta comum na Internet.
- Existem também outras versões dos códigos: relocação temporária do arquivo solicitado, erro interno do servidor, movimentação final. Nesse caso, o usuário será redirecionado. Se o código 500 aparecer, significa que o servidor está com defeito.
URL - o que é isso?
URL é o coração da comunicação da Web entre o cliente eservidor. A solicitação geralmente é enviada por meio de URL - um único índice de recurso. A estrutura da solicitação de URL é muito simples. Consiste em vários elementos: protocolo http (cabeçalho), hoot (endereço do site), porta, caminho de recursos e consulta.
O protocolo também está disponível paraconexões https e troca de informações. O URL contém informações sobre a localização de um site específico na Internet. O endereço inclui o nome do domínio, o caminho para a página e seu nome.
A principal desvantagem de trabalhar com URLs é a interação inconveniente com o alfabeto latino, bem como números e símbolos. Na otimização de SEO, o endereço da URL desempenha um papel importante.

Recomendações úteis
Usuários ativos de computadores e desenvolvedores não querem se familiarizar com algumas recomendações profissionais que são dadas por especialistas neste campo:
- Designe as datas de expiração para arquivos e documentos, levando em conta as atualizações. A informação estatística é indicada em grandes valores de max-age.
- Um único documento deve ser acessível apenas por um URL.
- Se você atualizar um arquivo que será baixado pelo usuário, altere seu nome e um link para ele. Isso garante que um novo documento, não obsoleto, seja baixado.
- Os cabeçalhos Last-Modified devem corresponder à data atual das alterações de conteúdo mais recentes. Não guarde novamente páginas e documentos, se não os alterar.
- Use solicitações POST somente quando necessário. Minimize o trabalho com SSL.
- Cabeçalhos antes de enviar o servidor devem ser verificados com o plugin REDbot. </ ul </ p>